Viktor Alm
Grundare av Veratyr.ai and Labelf.ai. Bygger AI-produkter sedan 2005 — över 20 år och det fortsätter.
Artiklar
1 mars 2021
Kan AI hjälpa till att designa vår maskot?
Vi beställde designförslag från frilansare och jämförde dem med vad AI kunde generera. Resultaten var överraskande.
Läs artikel
19 maj 2026
Hur Oslo blir Stockholm — och Stockholm blir Silicon Valley
Buy versus build, tidigt kapital, och varför vi måste sluta bygga internt om vi vill ha ett ekosystem som flyger.
Läs mer
1 mars 2026
Del 1 av 1Hur man lär en sten ord
Från Word2Vec till Attention — hur maskiner lärde sig förstå ord, med interaktiva visualiseringar.
Läs mer
1 mars 2026
När maskinerna kom till bönderna
Vad den agrara revolutionen lär oss om AI:s påverkan på den globala arbetskraften — med interaktiva datavisualiseringar.
Läs mer
28 februari 2021
En AI-genererad konstupplevelse
Hur långt har AI (deep learning) kommit? Vi testade att skapa en helt AI-genererad upplevelse.
Läs mer
11 januari 2021
Vad är Narrow AI? (Del 1)
Den AI vi har idag kallas för Narrow AI. Här är vad det faktiskt innebär för dig som vill använda deep learning i praktiken.
Läs mer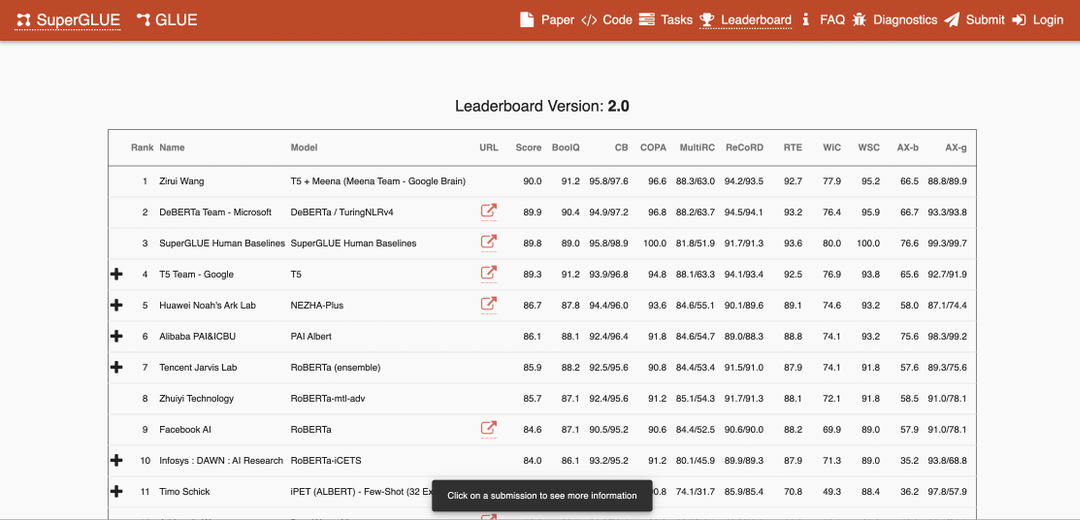
31 december 2020
AI slår människans baslinje på SuperGLUE
Hur vi mäter AI:s framsteg och vad det faktiskt innebär när maskinen presterar bättre än oss.
Läs merJag plockar isär saker för att förstå hur de fungerar, och sedan bygger något bättre.




Videor
12 oktober 2023 · Kontakta
Så enkelt hittar du dina "Rootcauses" & ökar din försäljning!
17 juni 2022 · Labelf AI
Can AI be sentient? Get to know the current status of AI from Google's LaMDA
11 december 2019 · Viktor Alm
Kan AI skriva texter? | AI och Data #2
3 december 2019 · Viktor Alm