Viktor Alm
Founder of Veratyr.ai and Labelf.ai. Building AI products since 2005 — over 20 years and counting.
Articles
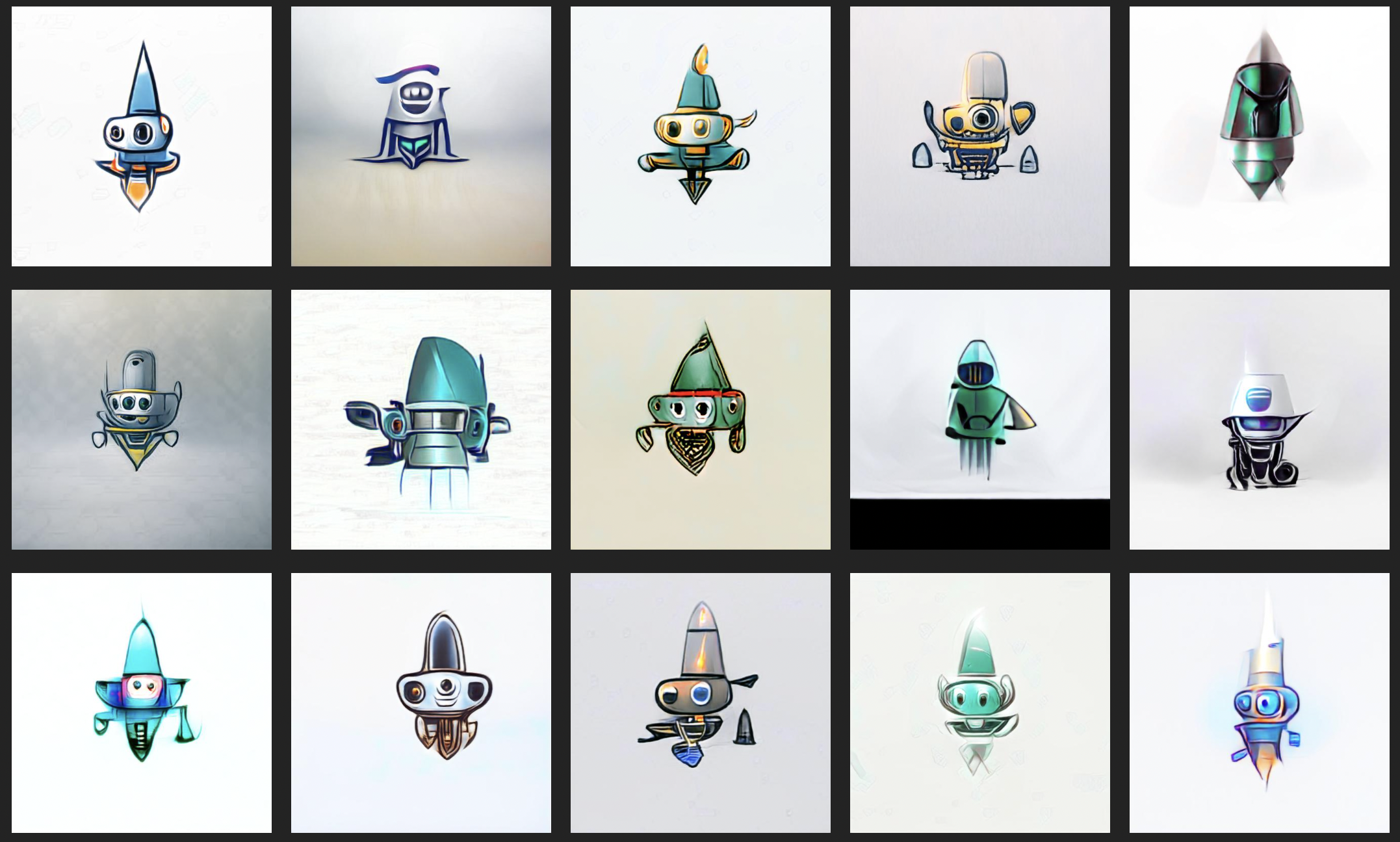
March 1, 2021
Can AI Help Design Our Mascot?
We ordered designs from freelancers and compared them to what AI could generate. The results were surprising.
Read article
May 19, 2026
How Oslo Becomes Stockholm — and Stockholm Becomes Silicon Valley
Buy versus build, early capital, and why we have to stop building everything in-house if we want an ecosystem that actually flies.
Read more
March 1, 2026
Part 1 of 1How to teach a rock words
From Word2Vec to Attention — how machines learned to understand words, with interactive visualizations.
Read more
March 1, 2026
When the Machines Came for the Farmers
What the Agricultural Revolution teaches us about AI's impact on the global workforce — with interactive data visualizations.
Read more
February 28, 2021
An AI-Generated Art Experience
How far has AI (deep learning) come? We tested creating a fully AI-generated experience.
Read more
January 11, 2021
What is "Narrow AI part 1"
The type of AI we currently have is Narrow AI. I will with two posts try to explain what that means in practice for someone wishing to utilize deep learning.
Read moreI pick things apart to understand how they work, then build something better.




Videos
October 12, 2023 · Kontakta
Så enkelt hittar du dina "Rootcauses" & ökar din försäljning!
June 17, 2022 · Labelf AI
Can AI be sentient? Get to know the current status of AI from Google's LaMDA
December 11, 2019 · Viktor Alm
Kan AI skriva texter? | AI och Data #2
December 3, 2019 · Viktor Alm