Understanding AI progress and its current capabilities
I often wonder why people do not spend more time to understand what AI can do. The best way I think, is to look at the tasks that are "solved", that work. This is both inspiring and greatly reduces the risks. These are problems "I" could solve given a competent enough team and budget. The best way I think is not to start looking at the basics or the math which is my main guess as for why people know so little.
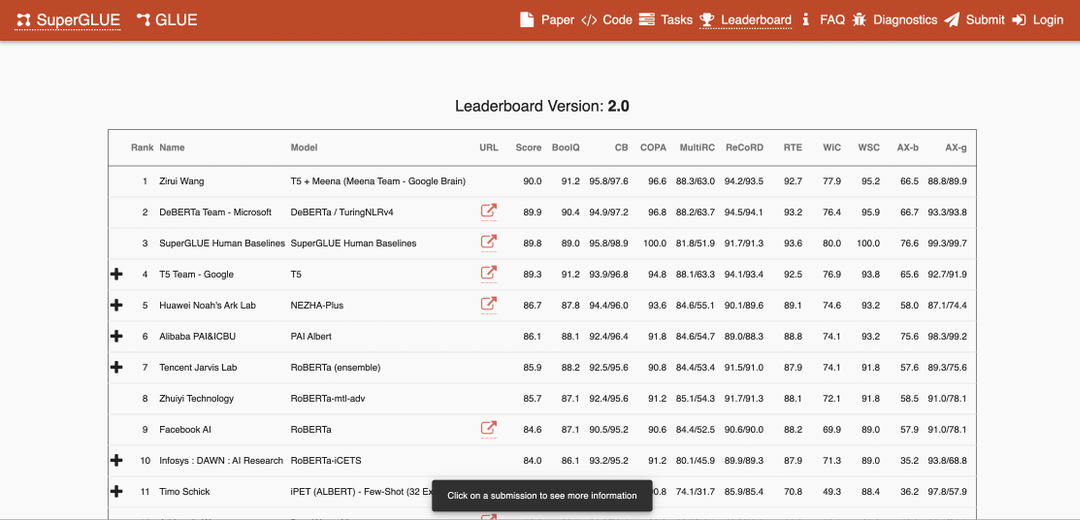
So where do we start? Let's have a look at the tasks currently used to measure AI-models capability for language understanding. The Super General Language Understanding Evaluation Benchmark (SuperGLUE)
GLUE
A few years ago a set of tasks was collected to evaluate progress on AI research and language understanding. It was called GLUE. Last year AI surpassed the human baselines.
SuperGLUE
The researchers however had a sense that these tasks would be beaten and gathered a set of new tasks, called SuperGLUE. It involves QA and other more difficult tasks. But its naming might be a bit misleading. It is not really Super general language understanding from a human perspective, but compared to where the field of AI was before the introduction of "true" deep learning models like Transformers and its continuations such as BERT and Electra it seems general.
VentureBeat Article on its release
2020
Just before the start of 2021, SuperGLUE was beaten by a team from Microsoft. 12 hours after Microsoft's submission it was beaten again by a Google researcher. We need even more difficult tasks now. But how can you benefit from this progress?
 General Language Understanding
General Language Understanding
Let's have a look through the SuperGLUE tasks with examples and how AI's results compare with humans.
1. BoolQ
This is a great task for question answering. Is the answer to the question yes or no given a source? Similar systems to these will be everywhere in a few years time. We are currently experimenting with various ways on how to make this incredibly easy for you to implement.
Question
do iran and afghanistan speak the same language
Passage
Persian language -- Persian (/ˈpɜːrʒən, -ʃən/), also known by its endonym Farsi (فارسی fārsi), is one of the Western Iranian languages within the Indo-Iranian branch of the Indo-European language family. It is primarily spoken in Iran, Afghanistan (officially known as Dari since 1958), and Tajikistan (officially known as Tajiki since the Soviet era), and some other regions which historically were Persianate societies and considered part of Greater Iran. It is written in the Persian alphabet, a modified variant of the Arabic script, which itself evolved from the Aramaic alphabet.
Answer
True
BoolQ (Boolean Questions, Clark et al., 2019a) is a QA task where each example consists of a short passage and a yes/no question about the passage. The questions are provided anonymously and unsolicited by users of the Google search engine, and afterwards paired with a paragraph from a Wikipedia article containing the answer. Following the original work, we evaluate with accuracy.
Human score: 89.0AI score: 91.2
2. CommitmentBank
This is very similar to the tasks of GLUE. The main use for these are comparing sentences/texts and see similarities or entailments/contradictions. The progress made in this area will benefit you directly through Labelf where we make extensive use of these models for text classification.
Premise
It was a complex language. Not written down but handed down. One might say it was peeled down.
Hypothesis
the language was peeled down
Answer
Entailment (Entailment, Neutral or Contradiction)
The CommitmentBank (De Marneffe et al., 2019) is a corpus of short texts in which at least one sentence contains an embedded clause. Each of these embedded clauses is annotated with the degree to which we expect that the person who wrote the text is committed to the truth of the clause. The resulting task framed as three-class textual entailment on examples that are drawn from the Wall Street Journal, fiction from the British National Corpus, and Switchboard. Each example consists of a premise containing an embedded clause and the corresponding hypothesis is the extraction of that clause. We use a subset of the data that had inter-annotator agreement above 0.85. The data is imbalanced (relatively fewer neutral examples), so we evaluate using accuracy and F1, where for multi-class F1 we compute the unweighted average of the F1 per class.
Train size: 250 — Accuracy/F1
Human score: 95.8/98.9AI score: 95.8/97.6
3. The Choice Of Plausible Alternatives (COPA)
Does the model contain some sort of information of what might be the most plausible connection/reason. Does it "understand" anything about the world through questions about cause and effect?
Premise
My body cast a shadow over the grass.
Question
Cause
Option 1
The sun was rising
Option 2
The grass was cut
Answer
Option 1 (The sun was rising)
The Choice Of Plausible Alternatives (COPA, Roemmele et al., 2011) dataset is a causal reasoning task in which a system is given a premise sentence and two possible alternatives. The system must choose the alternative which has the more plausible causal relationship with the premise. The method used for the construction of the alternatives ensures that the task requires causal reasoning to solve. Examples either deal with alternative possible causes or alternative possible effects of the premise sentence, accompanied by a simple question disambiguating between the two instance types for the model. All examples are handcrafted and focus on topics from online blogs and a photography-related encyclopedia. Following the recommendation of the authors, we evaluate using accuracy.
Train size: 400 — Accuracy
Human score: 100AI score: 98.4
4. MultiRC
This task is similar to BoolQ but actually contains the answer to the question and can be viewed as a fact checker given a premise, a question and an answer.
Premise
While this process moved along, diplomacy continued its rounds. Direct pressure on the Taliban had proved unsuccessful. As one NSC staff note put it, "Under the Taliban, Afghanistan is not so much a state sponsor of terrorism as it is a state sponsored by terrorists." In early 2000, the United States began a high-level effort to persuade Pakistan to use its influence over the Taliban...
Question
What did the high-level effort to persuade Pakistan include?
Answer
Asking Pakistan to help the USA
Verdict
True
The Multi-Sentence Reading Comprehension dataset (MultiRC, Khashabi et al., 2018) is a true/false question-answering task. Each example consists of a context paragraph, a question about that paragraph, and a list of possible answers to that question which must be labeled as true or false. Question-answering (QA) is a popular problem with many datasets. We use MultiRC because of a number of desirable properties: (i) each question can have multiple possible correct answers, so each question-answer pair must be evaluated independent of other pairs, (ii) the questions are designed such that answering each question requires drawing facts from multiple context sentences, and (iii) the question-answer pair format more closely matches the API of other SuperGLUE tasks than span-based extractive QA does. The paragraphs are drawn from seven domains including news, fiction, and historical text.
Train size: 27243 — Accuracy/F1
Human score: 81.8/51.9AI score: 88.2/63.7
5. ReCoRD (Reading Comprehension with Commonsense Reasoning Dataset)
Is the model able to understand what entities in the text are being referred to?
Premise
The harrowing stories of women and children locked up for so-called 'moral crimes' in Afghanistan's notorious female prison have been revealed after cameras were allowed inside. Mariam has been in Badam Bagh prison for three months after she shot a man who just raped her at gunpoint and then turned the weapon on herself - but she has yet to be charged. Nuria has eight months left to serve of her sentence for trying to divorce her husband. She gave birth in prison to her son and they share a cell together...
Query
The baby she gave birth to is her husbands and he has even offered to have the courts set her free if she returns, but @placeholder has refused.
Options
"Afghanistan", "Badam Bagh", "Mariam", "Nuria"
Answer
Nuria
(Reading Comprehension with Commonsense Reasoning Dataset, Zhang et al., 2018) is a multiple-choice QA task. Each example consists of a news article and a Cloze-style question about the article in which one entity is masked out. The system must predict the masked out entity from a given list of possible entities in the provided passage, where the same entity may be expressed using multiple different surface forms, all of which are considered correct. Articles are drawn from CNN and Daily Mail. Following the original work, we evaluate with max (over all mentions) token-level F1 and exact match (EM).
Train size: 100730
Human score: 91.7/91.3AI score: 94.5/94.1
6. Recognizing Textual Entailment (RTE)
Similar to CB, this task compares texts and see if they support each others claims or contradicts/says nothing about each other.
Premise
No Weapons of Mass Destruction Found in Iraq Yet.
Hypothesis
Weapons of Mass Destruction Found in Iraq.
Answer
False
The Recognizing Textual Entailment (RTE) datasets come from a series of annual competitions on textual entailment, the problem of predicting whether a given premise sentence entails a given hypothesis sentence (also known as natural language inference, NLI). RTE was previously included in GLUE, and we use the same data and format as before: We merge data from RTE1 (Dagan et al., 2006), RTE2 (Bar Haim et al., 2006), RTE3 (Giampiccolo et al., 2007), and RTE5 (Bentivogli et al., 2009). All datasets are combined and converted to two-class classification: entailment and not_entailment. Of all the GLUE tasks, RTE was among those that benefited from transfer learning the most, jumping from near random-chance performance (~56%) at the time of GLUE's launch to 85% accuracy (Liu et al., 2019c) at the time of writing. Given the eight point gap with respect to human performance, however, the task is not yet solved by machines, and we expect the remaining gap to be difficult to close.
Train size: 2490
Human score: 93.6AI score: 93.2