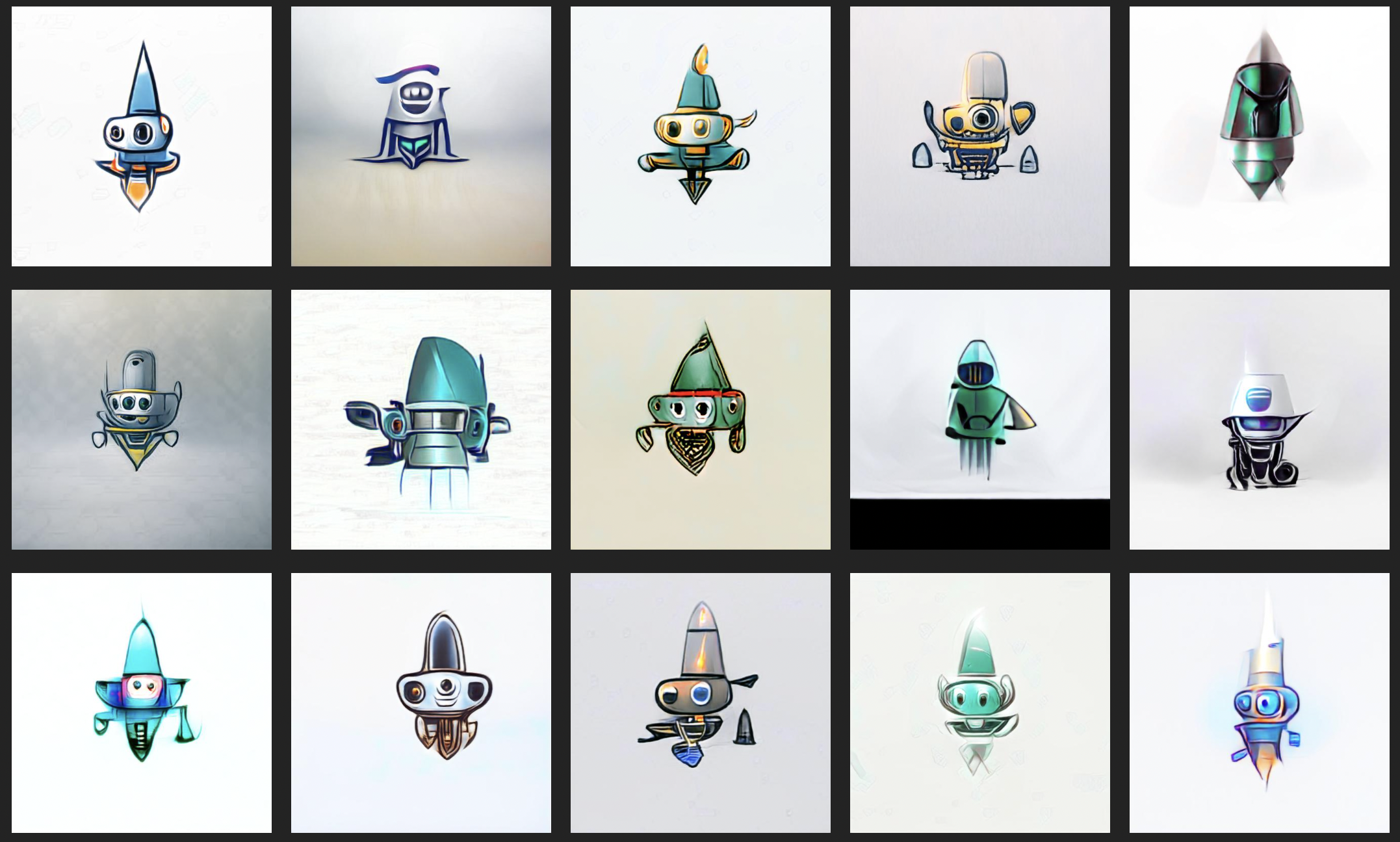
How far has AI (deep learning) come today?
In recent years there have been enormous advances, and we've been thinking about ways to communicate and demonstrate this. We started a small project to create a fully "AI"-generated experience. The videos we see are created by 3 different models:
- Model 1 was trained to write Swedish poems.
- Model 2 is a model trained to draw.
- Model 3 is a model trained to understand the connections between text and image. It tries to "understand" what a text looks like, and how an image can be described.
With these, we built an automated system that writes a poem, and then animates this poem to life in a video through a flowing artwork consisting of about 45 frames per second.
Example 1
We're trying to test how much of the world the models managed to compress ("understand"), but also to test the potential for creativity. Take cubism. Cubes exist, the real world exists. Compress these two and out comes something new yet old. Is creativity partly some form of looking at the midpoint of what is being compressed? What neural networks are good at is compression, so if that thesis holds somewhat true, AI should be a fantastic tool for creativity.
We use this approach and "prompt" (instruct via text that the model takes as input) the output to be in the style of two artists at all times, and the jerkiness we see in the video is a "battle" between the model's interpretation of these artists and the previous line of poetry, plus some programmed randomness around what's most important. The poem, artist 1, or artist 2.
Example 2
What's really interesting is that BigGAN is trained on a dataset called ImageNet. It's images of dogs, cats, and cars. It's not a model trained to create artworks that learned to make artworks. But in the midpoint between a cassette player, a kangaroo, and a kitchen, there are things that resemble robots or artworks. Searching through this model's space of possible outputs leads to finding exciting things in the middle of normal things.
Example 3
Example 4
Example 5
Example 6
To further test this idea of creativity, interpretation, and compression, Per added an image of a brain that the model should also take into account when painting. That's why this video is a bit different, and sometimes it manages to weave the brain into the artwork really well!
Here's a live example of Per experimenting. Brain, sun, autumn, and van Gogh/general expressionism.

Example 7
If you then swap out which model handles the image generation, you suddenly get a completely new style! This model divides the image into different tiles in a codebook, and this leads to the model sometimes ending up in a state where it fills different parts of the instructions in different tiles! Cool!
But if we're going to get practical, how can these models help businesses?
We ourselves have practical uses for it — for example, we're planning to have some nice giveaways and cool artwork at the office. This is a personal favourite variant of our logo that I'd love to have as a t-shirt or booth decoration in the future!
Summary
Models like CLIP have become incredibly good at understanding both text and image. This is very promising for a very near future where models have had audio, image, and text as training material.
We're moving quickly toward a future where you can tell your new streaming service that you want to watch a movie about Indiana Jones in northern Sweden hunting for the golden wolverine with yourself as the sidekick. Infinite content. Until then, we'll have to endure an infinite number of "deep" poems and their illustrations.
I should add that we selected our favourites to post here — this is not an exact representation of all the content that was generated.
Last but not least, thanks to those who developed the models/architectures we used:
BigGAN — Large Scale GAN Training for High Fidelity Natural Image Synthesis Andrew Brock, Jeff Donahue, Karen Simonyan arxiv.org/abs/1809.11096
CLIP — Learning Transferable Visual Models From Natural Language Supervision Alec Radford, Jong Wook Kim et al OpenAI Paper
DALL-E — Zero-Shot Text-to-Image Generation Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, Ilya Sutskever arxiv.org/abs/2102.12092
GPT-2 — Language Models are Unsupervised Multitask Learners Alec Radford et al OpenAI Paper
Litteraturbanken — litteraturbanken.se
Methods inspired and developed from Ryan Murdocks initial method @adverb