

Introduction
Continuing the pre-training process and making a "Domain adaptation" of an existing model can be a quick and easy way to get some extra percentage points in accuracy. If you are going to do different classification tasks where bias in models' data can have negative consequences, you must have total control over everything the model has seen and then you have no alternative but to train from scratch. Maybe you have extra long examples in your datasets or a domain with very specific jargon. There may not even be trained models in the language you want to use from the beginning. These are all valid reasons to get into pre-training of models.
Model
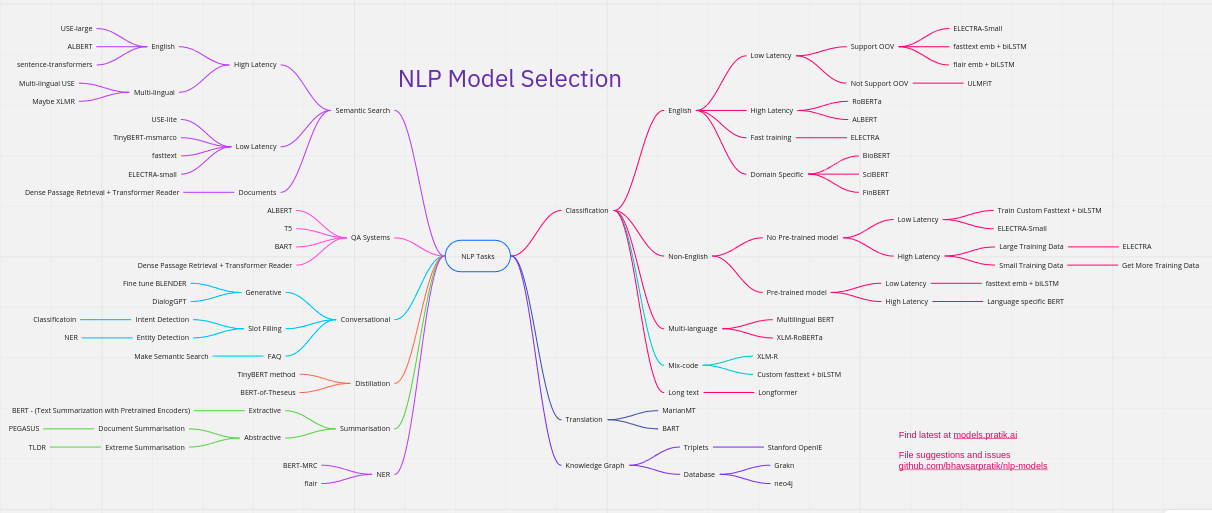
Which model should you choose? It depends on the problem you want to solve.
How much compute do you have? How much data do you have? How much help can you get? How much time do you have? How much can inference cost? Transform text? T5, BART. Understand text? Electra, Roberta. Fast inference? Prune, distill, ALBERT. Write? GPT
Data
It all starts with data. The optimal situation would be that you have a large amount of data from similar processes you intend to implement the model on. If you want a model for assessing school exams about the Roman Empire, it can be good to have general data about antiquity and other history submissions before you move on to training the model to specifically correct texts about the Roman Empire. If you have found a new exciting architecture or just want to experiment, there are open data that do not require different organizations' closed data.
Trying to balance datasets and get them to follow the prevailing culture's perceptions of different words is extremely difficult. The model becomes a direct reflection of the data. In itself, it becomes a general reflection of how people use language, but not necessarily how you want or think it should be. Here it becomes almost necessary to go into gray areas around data collection if you are looking to create a model with a consciously designed language understanding. Always think about how balanced it is, how well it reflects reality and / or the goal you want to achieve. You also need insane amounts.
Tokenization
Tokenization works as a kind of compression / division of words. You can see demos of this on my page "Högskoleprovet". Usually word comprehension / context comprehension works well with only a few letters per token, but the total length of text the model can read is definitely limited by the fact that each token only consists of a few letters instead of words. It is therefore usually wiser to train with your own vocab. I have tried to train different English models that had ÅÄÖ in the vocabulary but the text length is halved. It may be an idea to extend the vocabulary to utilize the resources put into training the model if you want to do a POC.
Here are some of the methods and no one truely feels optimal. There are BPE-based and sentencepiece with unigram. Unfortunately, Swedish has a lot of compound words for which these algorithms are not made. Right now I think we will end up with some character-based layers that then move towards words and possibly sentences / paragraphs.
Encode / Decode data
When you take a dataset and tokenize it with your vocab, it is extremely important to check how it works. Many tokenizers are specialized to be in just one language. Bert / Albert / Electra's tokenizer is one such example.
If you want one with lowercase, it always strips accents:
if self.do_lower_case:
token = token.lower()
token = self._run_strip_accents(token)text = unicodedata.normalize("NFD", text)
Or this in Albert's tokenizer:
outputs = unicodedata.normalize("NFKD", outputs)
english_chars = set(list("abcdefghijklmnopqrstuvwxyz"))
The key is to test, test before you start training for real. It can be costly to train a model like this, and you do NOT want to be wrong. Tokenize to ids and back. Convert your TFRecords back to text and see if something changed. Check out the masks. Definitely take a few days to get acquainted with how this works before you start. Because it's usually not just in one file that hardcoded stuff like this lurks.
Pretraining
For Decoders / Auto-regressive models, the training task is quite simple. Guess the next token. When it comes to Encoders or Decoders, it is not as simple.
Compute/FLOPS
Google has TPUs and GPUs in the Google Cloud Platform. Most models available are directly compatible with TPUs and are ready to go!
Encoder
Masked Language Modeling. BERT masks tokens in training samples. Generating these training samples on over 100GB of data with maybe 40 different generated masks from one sample generates insane amounts of text data. Multiple TBs. I limited myself to 25 examples with a few runs. Renting servers to generate all that data was expensive. Several tens of thousands of kronor, but it saved me some time for that method. It reduces randomness in training and makes each run see approximately the same tasks. However, this does not matter much if you only want to train a couple of models. Therefore, you can just as easily generate samples on the fly. Then there are different strategies for how to mask tokens. Do you mask tokens, words or spans? What tokens do you mask? This is something you have too look into a bit. Then there are variants such as XLNet and Electra.
Electra uses an MLM model called a generator and a model that guesses which tokens have been changed. This is a VERY effective method for training models. Sometimes up to 1/4 of the compute.
Encoder/Decoder
Here I have not had time to experiment enough yet. Only trained one model from scratch. English to Swedish, but i have a few more experiments underway. Here is a bit of a mix of how to train and what methods. T5, BART, MARGE, back-translation, de-noising etc. I will add here after I have a little more practical experience from Pre-training on these models.
Training Parameters
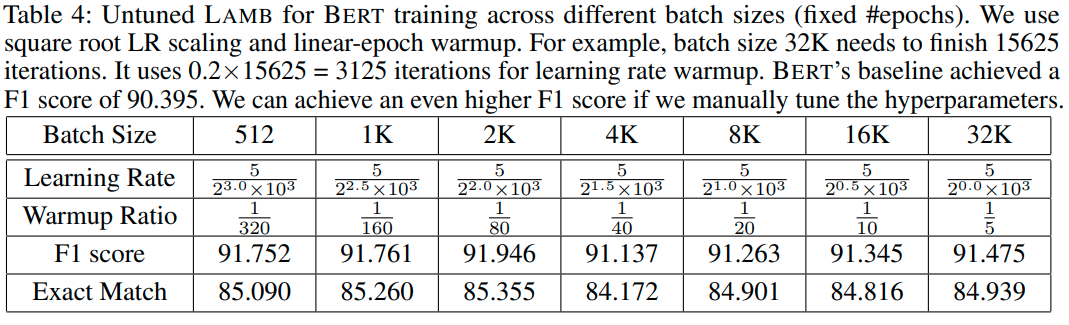
This is about reading papers for optimizers and checking the appendix. Often it is specified somewhere. I see alot of github issues on how to do it, or copy-paste from the first example that does not match their case at all and then trained for several weeks, people with PhDs... It is difficult to find good examples when things are new and it is largely a matter of testing and reading more papers to do the most correct thing at the moment. It's not as easy as just following the docs for some framework. Most are undocumented and sometimes you are lucky with a little code comment or some appendix. Even when there is clear instructions, people make strange mistakes. This is a great example LAMB, You, et al but people still miss it.
End use
You will soon discover shortcomings in the series of decisions you have made to get to this stage. You notice them when you test on different "fine-tuning" tasks. Down the rabbit hole we go!
Most often I try to find someone who has tried to solve similar tasks and check how the model has been fine-tuned or I go back and check settings for the task in GLUE that is most similar and work from there.


