
Inledning
Att ta en befintlig modell och köra lite "domain adaptation" kan vara ett snabbt sätt att krama ur några extra procent i precision. Men om du vill ha total kontroll — till exempel för att undvika bias i datan eller för att du har ett väldigt specifikt fackspråk — då finns det ingen återvändo: du måste träna från scratch. Kanske har du ett gigantiskt dataset eller så jobbar du med ett språk där det helt enkelt inte finns några bra modeller ännu. Det är då det blir riktigt spännande (och svårt).
Vilken modell ska man välja?
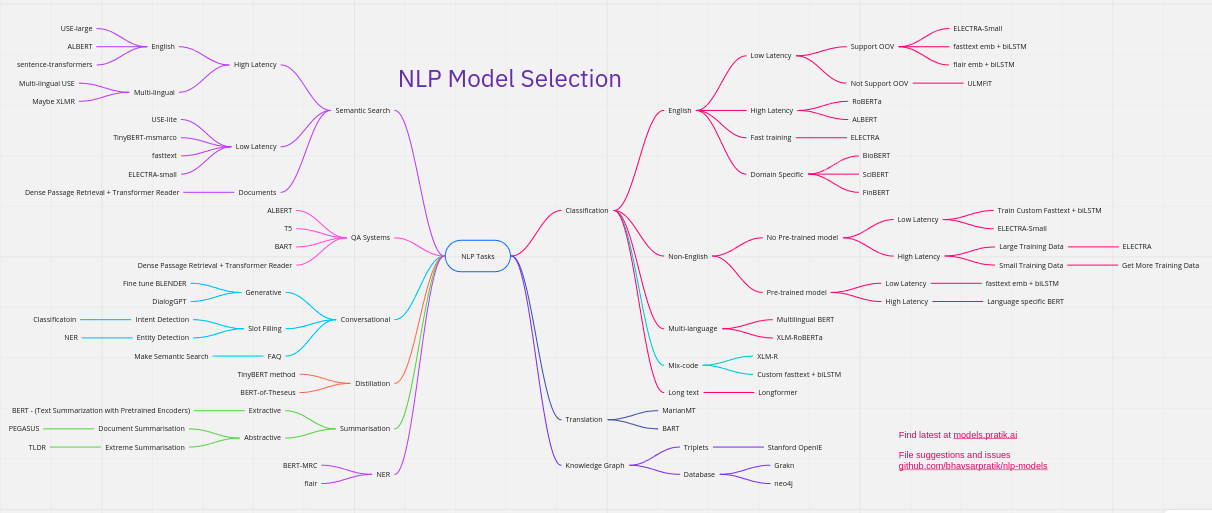
Allt kokar ner till vilket problem du försöker lösa. Hur mycket beräkningskraft (compute) har du? Hur mycket data sitter du på? Och hur mycket får det kosta när modellen väl ska användas (inference)?
Ska du förvandla text (översättning, sammanfattning)? Kolla på T5 eller BART.
Ska du förstå text (klassificering, sök)? Electra eller RoBERTa är dina vänner.
Behöver du snabb inferens? Då är det ALBERT, prunning eller distillation som gäller.
Ska du skriva text? Då är det GPT-familjen du letar efter.
Allt börjar med data
Utan bra data är du rökt. Det optimala är om du har massor av text som liknar det modellen faktiskt ska jobba med senare. Ska du bygga en AI som rättar skoluppgifter om romarriket? Då behöver du mata den med massor av texter om antiken och historia innan du finjusterar den på själva uppgifterna.
Att balansera ett dataset så att det faktiskt speglar den kultur och de värderingar vi har är extremt svårt. Modellen blir en spegel av datan — på gott och ont. Den kommer att reflektera hur folk faktiskt använder språket, inte nödvändigtvis hur vi önskar att de använde det. Här hamnar man ofta i etiska gråzoner kring datainsamling om man vill designa en specifik typ av språkförståelse. Och kom ihåg: du behöver vansinniga mängder data.
Tokenization: Det dolda hindret
Tokenization är sättet vi komprimerar och delar upp ord så att datorn fattar dem. (Du kan se demos på detta under Högskoleprovet). Det är oftast smartast att träna med ett eget "vocab" (vokabulär). Jag har testat att köra engelska modeller som visserligen har ÅÄÖ i sitt vocab, men då halveras ofta den effektiva textlängden eftersom de svenska tecknen tar för mycket plats.
Svenska är dessutom lurigt med alla våra sammansatta ord. De flesta standardalgoritmer (som BPE eller SentencePiece) är inte byggda för det. Just nu tror jag vägen framåt är "character-based layers" som gradvis rör sig mot ord och stycken.
Testa, testa, testa!
Innan du bränner tiotusentals kronor på träning: kolla din tokenizer! Många är hårdkodade för engelska. Om du till exempel kör do_lower_case i BERT/ALBERT-tokenizers så strippar de ofta bort accenter — vilket i praktiken raderar våra kära ÅÄÖ.
# Det här raderar ÅÄÖ om man inte ser upp!
text = unicodedata.normalize("NFD", text)
Nyckeln är att köra "round-trips": Tokeniza till ID:n och konvertera tillbaka till text. Ser det likadant ut? Om inte, har du problem. Lägg några dagar på att bekanta dig med koden — hårdkodade engelska antaganden lurar överallt.
Pre-training: Nu kör vi
För modeller som GPT (Decoders) är uppgiften enkel: gissa nästa ord. För BERT och liknande (Encoders) är det lite mer komplicerat.
Compute & FLOPS
Jag kör oftast på Google Cloud med deras TPU:er. De flesta moderna modeller är byggda för att lira direkt med dem, och det går undan!
Encoder (BERT, Electra)
Att generera träningsdata för MLM (Masked Language Modeling) på 100GB text kan skapa flera terabyte av temporär data. Det är dyrt att hyra servrar bara för att tugga igenom det. Ett tips är att använda Electra-metoden. Den använder en mindre modell (generator) för att byta ut ord, och en huvudmodell som ska gissa vilka ord som är fejk. Det är extremt effektivt — ibland kan du komma undan med 1/4 av beräkningskraften.
Encoder/Decoder (T5, BART)
Här experimenterar jag fortfarande en hel del. Det handlar om en mix av metoder som back-translation och de-noising. Jag kommer att uppdatera här när jag har fler konkreta resultat från mina svenska körningar.
Träningsparametrar
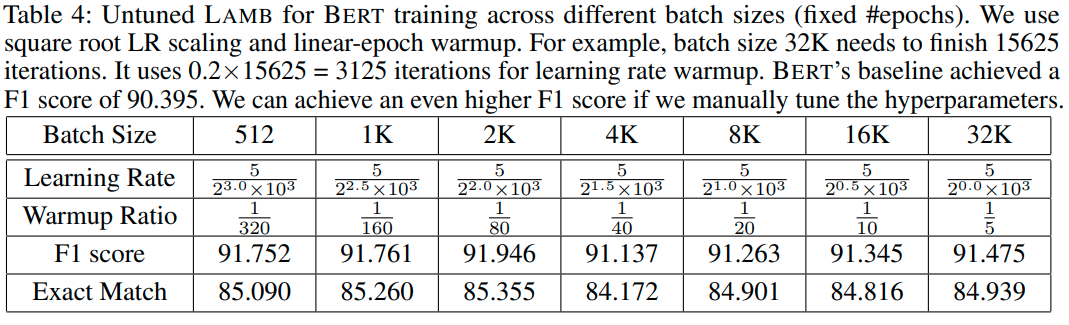
Här gäller det att lusläsa appendix i forskningsrapporterna. Det är fascinerande hur många, även folk med PhD:er, som bara copy-pastar inställningar från första bästa exempel och sedan låter träningen gå i veckor utan att det blir bra. Det mesta är odokumenterat. Man får ha lite tur med kodkommentarer eller hitta rätt tabell i en PDF. Ett klassiskt exempel är LAMB-optimeraren — missar man detaljerna där så spelar det ingen roll hur mycket compute man kastar på problemet.
Slutstationen
När du väl är klar kommer du att upptäcka alla brister i de beslut du tog längs vägen. Det är då du märker det på dina "fine-tuning" tasks. Grattis — nu är du officiellt nere i träsket!
Mitt bästa råd: hitta någon som gjort något liknande, kolla deras inställningar i GLUE-tester och använd det som din norrstjärna. Lycka till!


