Hur vi mäter AI:s kapacitet
Jag fattar inte varför fler inte lägger tid på att förstå vad AI faktiskt kan göra idag. Det absolut bästa sättet att få grepp om det är att titta på de uppgifter som redan är "lösta". Det är både inspirerande och avmystifierande — det här är problem som går att lösa nu, förutsatt att man har rätt team och budget.
Mitt bästa tips är att inte börja med matematiken bakom. Det är där de flesta tappar intresset. Börja istället med vad systemen faktiskt presterar.
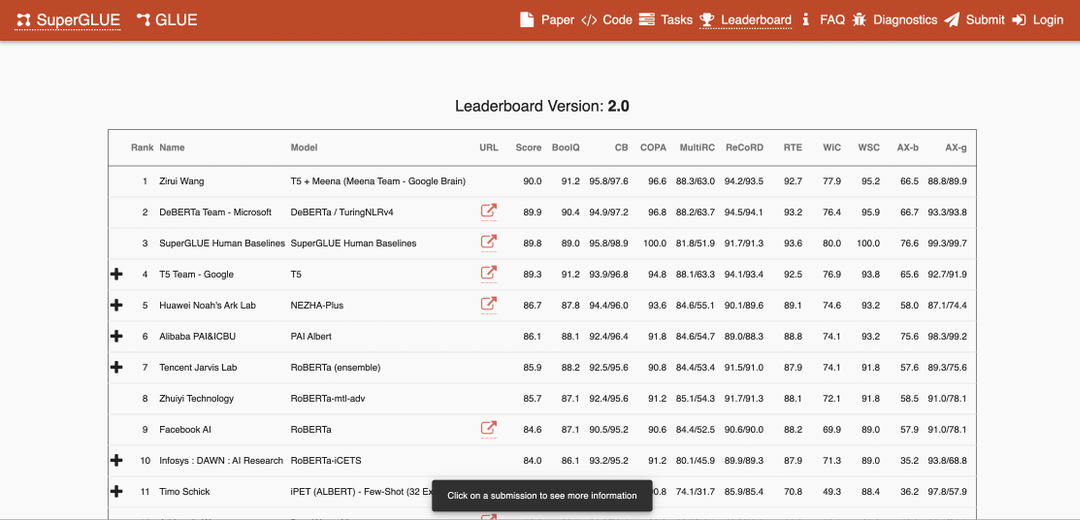
Låt oss titta på SuperGLUE (Super General Language Understanding Evaluation Benchmark) — mätstocken vi använder för att se hur bra modeller förstår språk.
Från GLUE till SuperGLUE
För några år sedan skapades GLUE för att utvärdera AI-forskningens framsteg. Det dröjde inte länge förrän AI-modellerna dundrade förbi människans resultat.
Forskarna insåg att de behövde något tuffare och skapade SuperGLUE. Det handlar om Question Answering (QA) och andra komplexa språkutmaningar. Namnet är lite missvisande — det är inte "supergenerellt" ur ett mänskligt perspektiv, men jämfört med hur det såg ut innan Transformers (som BERT och Electra) dök upp, så är det ett enormt kliv framåt.
2020: Milstolpen
Precis innan vi klev in i 2021 blev SuperGLUE-rekordet slaget av ett team från Microsoft. Bara tolv timmar senare blev de brädade av en Google-forskare. Vi behöver uppenbarligen ännu svårare tester nu. Men vad innebär det här för dig i praktiken?

Här är några exempel på vad SuperGLUE faktiskt testar, och hur AI står sig mot oss människor.
1. BoolQ (Ja/Nej-frågor)
Det här är kärnan i modern QA. Kan modellen svara ja eller nej baserat på en textkälla? Inom några år kommer sådana här system finnas överallt.
Fråga: Talar man samma språk i Iran och Afghanistan? Källa: Persiska (Farsi) talas primärt i Iran, Afghanistan (officiellt känt som Dari sedan 1958) och Tadzjikistan... Svar: Ja (Sant)
Människa: 89.0 | AI: 91.2
2. CommitmentBank (Logik och sanning)
Här handlar det om att avgöra om ett påstående i en text är sant, falskt eller om det råder osäkerhet.
Premiss: Det var ett komplext språk. Inte nedskrivet utan nedärvt. Man skulle kunna säga att det var nedskalat. Hypotes: Språket var nedskalat. Svar: Ja (Logisk följd)
Människa: 95.8 | AI: 95.8
3. COPA (Orsak och verkan)
Har modellen en rimlig uppfattning om hur världen fungerar?
Premiss: Min kropp kastade en skugga över gräset. Fråga: Vad var orsaken? Alternativ 1: Solen gick upp. Alternativ 2: Gräset var klippt. Svar: Alternativ 1
Människa: 100 | AI: 98.4
4. MultiRC (Läsförståelse)
Liknar BoolQ men kräver att modellen hittar exakta svar i längre stycken. En ren "fact checker".
Fråga: Vad innebar högnivåarbetet med att övertala Pakistan? Svar: Att be Pakistan hjälpa USA. Bedömning: Sant
Människa: 81.8 | AI: 88.2
5. ReCoRD (Logiskt tänkande)
Klarar modellen att förstå vem eller vad som refereras till i en text?
Fråga: Barnet hon födde är hennes mans... men @placeholder har vägrat. Alternativ: Mariam, Nuria, Afghanistan, Badam Bagh. Svar: Nuria
Människa: 91.7 | AI: 94.5
6. RTE (Textuell implikation)
Motsäger påståendena varandra eller backar de upp varandra?
Premiss: Inga massförstörelsevapen har hittats i Irak ännu. Hypotes: Massförstörelsevapen hittade i Irak. Svar: Falskt (Motsägelse)
Människa: 93.6 | AI: 93.2