Den AI vi har idag kallas för Narrow AI. I två inlägg försöker jag förklara vad det innebär i praktiken för den som vill använda deep learning.
Narrow AI: Snäv men effektiv
Dagens AI-modeller är tränade på begränsad data för att lösa en enda, specifik uppgift. Det är det vi kallar Narrow AI. Ett klassiskt exempel är att avgöra om en filmrecension är positiv eller negativ. För bara några år sedan var man tvungen att träna en modell enbart på just filmrecensioner för att den skulle förstå någonting alls.
Om du körade ett AI-projekt för bara ett par år sedan är din modell troligen alldeles för snäv. De gamla modellerna var urusla på att hantera ny data. Idag har vi Transfer Learning, där Transformer-modeller lär sig förstå ord och sammanhang från gigantiska mängder text — allt från bloggar och forum till forskningsrapporter. Det gör att modellerna generaliserar mycket bättre. De gamla modellerna saknade helt enkelt "kunskap" om världen utanför din specifika träningsdata.
Här är varför det gamla sättet inte fungerade:
Exempel: Sentimentanalys av filmrecensioner
Den här filmen var fantastisk.
Den här filmen var bra.
Den här filmen var fruktansvärd.
Om ditt dataset inte råkade innehålla ordet "fantastisk" hade modellen ingen aning om att det var något positivt. Man tvingades bygga enorma listor med ord — men tänk om någon stavar fel? "fantasttisk"? Då rasar alltihop.
Sammanhanget är allt
Den här filmen var skit.
Den här filmen var the shit. (slang för att något är riktigt bra)
Samma ord kan betyda helt olika saker beroende på sammanhanget. Gamla metoder som Word2Vec försökte placera ord i ett koordinatsystem, men de saknade fortfarande förmågan att se hela meningen på en gång. Folk spenderade åratal på att bygga komplexa grammatikregler och listor utan att någonsin bli helt nöjda. Det krävdes experter för att ens få det att fungera hjälpligt.
Hur gör vi idag?
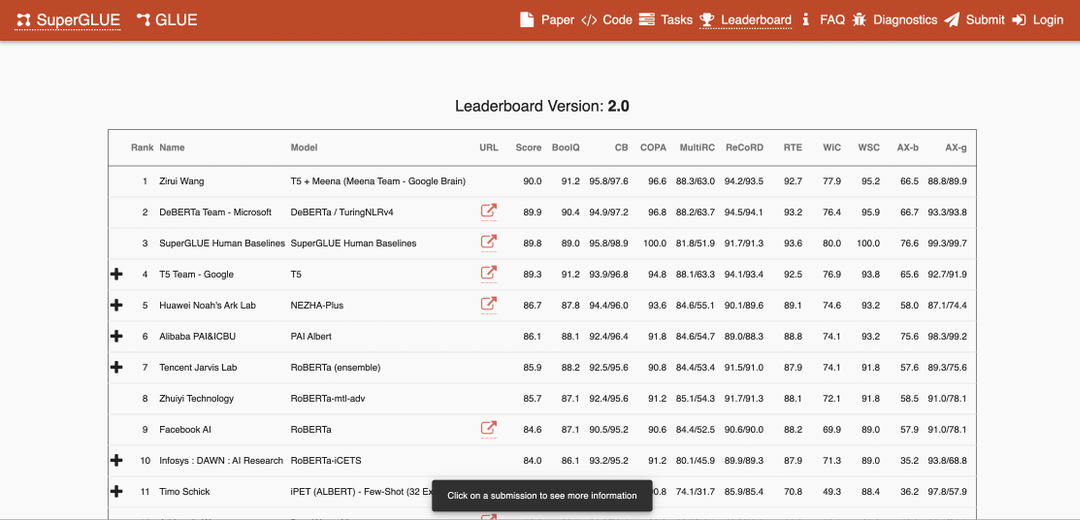
Vi använder de senaste arkitekturerna (som Transformers) för att lösa dessa problem direkt. Transformer-modeller har tagit världen med storm och är anledningen till att AI numera överträffar människan i läsförståelse på SuperGLUE-testet.
Vad krävs för att komma vidare?
 m0ar DATA
m0ar DATA
1. Mer och bättre data
Modeller blir fortfarande bättre om de får specifikt material, som juridiska texter för juridiska uppgifter (domain adaptation). Men med tillräckligt stora och varierade dataset kan vi nå en helt ny nivå av generaliserbarhet. Ett exempel är The Pile — 800 GB text från massor av olika källor.
2. Större och smartare modeller
Ju fler parametrar en modell har, desto bättre blir den på att dra slutsatser och generalisera. Metoder som retriever-baserade modeller (där AI:n kan "slå upp" fakta i en databas) eller Microsofts DeBERTa flyttar hela tiden gränserna för vad vi kallar "förståelse".
3. Smartare träning
Nya tekniker som Electra gör att modeller lär sig snabbare genom att gissa om ett ord i en mening blivit utbytt eller inte, istället för att bara gissa nästa ord. Det här gör träningen mer effektiv och resultaten mer robusta.
Elefanten i rummet...
Multimodal AI
Att träna ett system på olika typer av domäner som vision, språk och ljud kallas multimodal träning. För att en modell verkligen ska "förstå" en text kan det krävas visuella eller auditiva koncept. Behöver den ha känslor som sorg, ångest och smärta för att fullt ut förstå vår värld? Redan nu, bara genom att läsa slumpmässiga texter från internet, överträffar AI människan i både läsförståelse och språkförståelse.
Exempel
De flesta modeller som används i produktion idag är "single-modal" — de jobbar bara i en domän (oftast bara text). Men om en modell kan se och inte bara läsa, tror jag att den blir betydligt mer generell. Vi experimenterar med detta just nu, och storskaliga experiment tyder på att en vision-modell presterar ännu bättre om man kan baka in beskrivningar av bilderna i språket under träningen.
 Om vi ber en enkel modell att rita "a pony on a green field". Det här är resultatet efter bara en iteration — man ser tydligt att modellen har ett visuellt begrepp om hur scenen ser ut.
Om vi ber en enkel modell att rita "a pony on a green field". Det här är resultatet efter bara en iteration — man ser tydligt att modellen har ett visuellt begrepp om hur scenen ser ut.
 Testning med "one small horse on pasture" visar att modellen "tycker" att dessa koncept liknar varandra visuellt. Det är den övergripande "känslan" vi testar, inte den tekniska kvaliteten på bilden.
Testning med "one small horse on pasture" visar att modellen "tycker" att dessa koncept liknar varandra visuellt. Det är den övergripande "känslan" vi testar, inte den tekniska kvaliteten på bilden.
Vi är på väg mot en bredare "Narrow AI"-framtid!
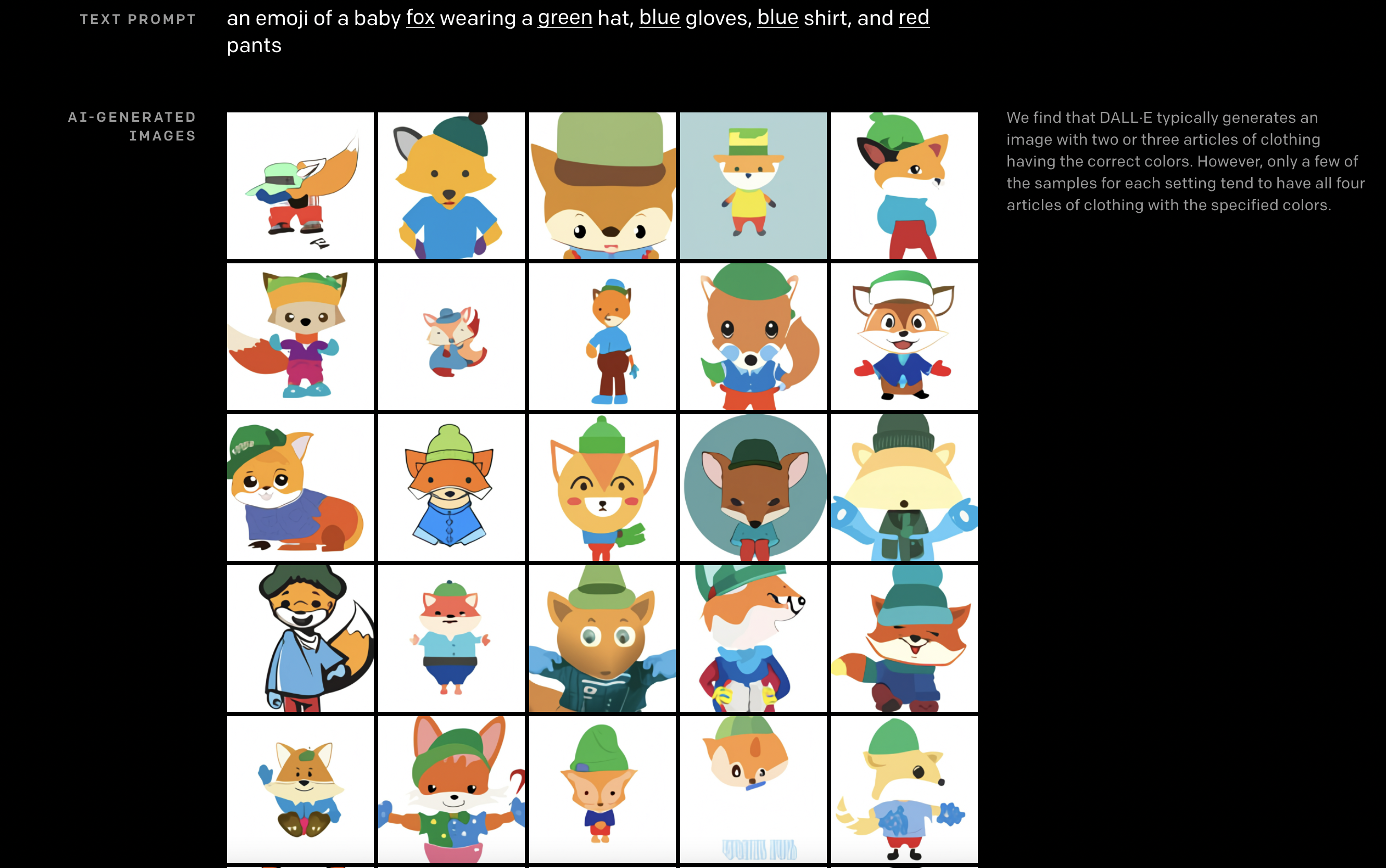 Skärmdump av OpenAI:s DALL-E, en multimodal decoder (liknande GPT-3) tränad för att generera bilder. Det här kommer att förändra allt.
Skärmdump av OpenAI:s DALL-E, en multimodal decoder (liknande GPT-3) tränad för att generera bilder. Det här kommer att förändra allt.